La presse et les sites Web consacrés à l’informatique retentissent de clameurs horrifiées depuis qu’ont été révélées, le 3 janvier 2018, les failles Meltdown et Spectre, et il y a de quoi. Ces vulnérabilités majeures ne résultent pas d’erreurs de programmation de tel ou tel logiciel, mais de caractéristiques des microprocesseurs, ce qui est plus grave et plus difficile à corriger. En effet, la prise de contrôle du matériel permet l’accès à tous les logiciels et à toutes les données du système, et à leur modification au gré de l’attaquant.
Comme beaucoup de choses exactes ont déjà été fort bien écrites, je n’entrerai pas ici dans les détails et renverrai le lecteur aux meilleures sources que j’ai trouvées.
J’emprunte à Daniel Miessler ce tableau récapitulatif :
| Meltdown | Spectre | |
|---|---|---|
| Architectures concernées | Intel | Intel, AMD, ARM |
| Prérequis pour l’intrusion | Pouvoir exécuter un programme sur le système cible | Pouvoir exécuter un programme sur le système cible |
| Méthode | Élévation de privilège + exécution spéculative | Prédiction de branchement + exécution spéculative |
| Impact | Accès à la mémoire du noyau depuis un processus ordinaire | Accès à la mémoire d’un processus depuis un processus d’un autre utilisateur |
| Correction provisoire | Modification de l’OS | Modification de l’OS (sans garantie) |
Les caractéristiques fonctionnelles des processeurs qui exécutent les programmes dans un ordinateur obéissent au modèle de von Neumann. Mais si von Neumann a donné un modèle fonctionnel de l’ordinateur, toujours valide, David Monniaux souligne avec raison qu’au fil de divers perfectionnements techniques les processeurs ont été dotés de caractéristiques non fonctionnelles, destinées à améliorer leurs performances, mais qui ne sont pas censées modifier les comportements et les résultats observés par l’utilisateur lorsqu’il soumet un programme à tel ou tel modèle d’ordinateur.
En principe, ces caractéristiques non fonctionnelles du processeur restituent un fonctionnement qui, vu de l’extérieur, est parfaitement conforme au modèle de von Neumann. Mais une exploitation malicieuse (au sens judiciaire du terme) de ces dispositifs permet d’accéder à des données en principe protégées. Rappelons brièvement quelques-uns de ces dispositifs :
Le pipe-line
Afin d’accélérer le traitement, les instructions machine élémentaires sont découpées en étapes successives encore plus élémentaires, ce qui permet de confier chaque étape à une unité de circuits logiques spécifique, par exemple unité de lecture du texte de l’instruction, unité de décodage, unité d’exécution, unité d’accès mémoire, unité de livraison du résultat. Ainsi le processeur peut commencer à traiter une instruction avant que la précédente soit terminée, en utilisant les unités libérées par la terminaison des premières étapes. Ce dispositif est nommé pipe-line.
Soient i1,i2,... i6 six instructions consécutives, elles seront traitées ainsi :
| i1 | FETCH | DEC | EXEC | MEM | RES | |||||
| i2 | FETCH | DEC | EXEC | MEM | RES | |||||
| i3 | FETCH | DEC | EXEC | MEM | RES | |||||
| i4 | FETCH | DEC | EXEC | MEM | RES | |||||
| i5 | FETCH | DEC | EXEC | MEM | RES | |||||
| i6 | FETCH | DEC | EXEC | MEM | RES |
Cette structure s’appelle un pipe-line, parce qu’elle évoque un tuyau dans lequel les instructions s’engouffrent les unes derrière les autres sans attendre que la précédente soit sortie. Nos instructions sont découpées en cinq étapes, ce qui fait que notre pipe-line à un moment donné contient cinq instructions en cours d’exécution : on dit que c’est un pipe-line à cinq étages. Certains processeurs ont des pipe-lines avec sept ou huit étages, voire plus : le Pentium III avait douze étages de pipe-line, le Pentium IV vingt, on ira jusqu’à 32 étages pour le Pentium IV E, avant de revenir à des profondeurs plus raisonnables parce que ces excès devenaient contre-productifs en termes notamment de dissipation thermique.
Processeurs super-scalaires
Les progrès de l’électronique font que les processeurs modernes disposent d’une profusion de transistors, trois milliards pour certains modèles. Cette abondance permet d’avoir, sur une même puce, plusieurs cœurs de processeurs, c’est-à-dire en fait plusieurs processeurs qui partagent la mémoire locale (on-board) et la connectique, mais aussi dans chaque cœur plusieurs unités de calcul, notamment pour les opérations d’arithmétique entière. Cela permet d’exécuter plusieurs instructions simultanément, avec bien sûr des problèmes de dépendance entre instructions et de synchronisation, dont nous allons voir comment essayer de les résoudre.
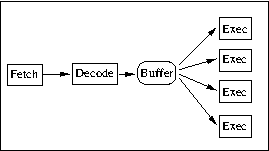
Exécution spéculative et prédiction de branchement
Parmi les caractères qui font qu’un ordinateur est plus qu’une simple calculette, il y a la possibilité, en fonction du résultat produit par une instruction, d’effectuer un test de ce résultat et, en fonction du test, de décider soit d’exécuter l’instruction suivante dans le texte du programme, soit d’en exécuter une autre, située ailleurs dans le texte : c’est ce que l’on nomme une alternative.
Les processeurs modernes, depuis en vingtaine d’années, sont en mesure de déterminer, entre les deux branches d’une alternative, avant de connaître le résultat du test, celle qui est la plus probable (par exemple en fonction des résultats des tests précédents). Ces processeurs commencent l’exécution de la séquence d’instructions la plus probable avant de savoir si elle sera véritablement choisie, quitte à restaurer les registres dans leur état antérieur (sauvegardé) si le test donne le résultat moins probable.
La prédiction de branchement est une variante du même mécanisme : un branchement est une bifurcation dans l’exécution d’un flot d’instructions, et de même le processeur anticipe quelle direction sera prise, avant que les tests soient effectués, quitte à revenir à l’état antérieur si cette anticipation est démentie par le test.
Exécution out of order
On imagine bien que les mécanismes du pipe-line et de l’exécution spéculative fonctionnent de façon plus ou moins efficace selon que le calcul effectué par telle ou telle instruction dépend ou non des résultats des calculs effectués par des instructions situées en amont dans le flot d’instructions. Afin de réduire ces dépendances, les processeurs modernes sont en mesure de modifier l’ordre d’exécution des instructions et de créer des variables intermédiaires, par exemple en renommant les registres.
Mémoire cache
Le mot cache, curieux retour au français d’un emprunt anglais, suggère ici l’idée de cacher dans un coin (techniquement parlant, dans une zone de mémoire petite mais à accès très rapide) pour l’avoir sous la main une chose que l’on ne veut pas avoir à aller chercher à la cave ou au grenier (i.e., dans la mémoire centrale, vaste mais à accès lent par rapport à la vitesse du processeur), pour gagner du temps. Cette technique s’est développée parce que, si la capacité de la mémoire centrale a évolué parallèlement à la puissance des processeurs, sa vitesse a progressé moins vite. Si au début des années 1990 le temps d’accès à une position de mémoire se mesurait en dizaines de cycles de processeurs, vingt ans plus tard c’est en centaines de cycles : il a fallu trouver des procédés pour éviter que cette discordance croissante ne réduise à néant les bénéfices obtenus pas l’accélération des processeurs.
La technique du cache procure des augmentations de performances très spectaculaires, bien qu’aucun modèle général satisfaisant de son fonctionnement n’ait pu être proposé à ce jour. Une variante en est le TLB (Translation Lookaside Buffer), qui conserve « sous la main » les résultats les plus récents de traductions d’adresses virtuelles en adresses réelles, ce qui permet avec un très faible volume de données d’obtenir des accélérations spectaculaires.
Les attaques Meltdown et Spectre reposent sur la manipulation astucieuse du cache : l’exécution spéculative permet l’accès à des zones mémoires non autorisées, opérations qui seront ensuite annulées, mais qui laisseront dans la mémoire cache des traces exploitables (à condition d’avoir construit habilement un programme à cet effet, ce qui n’est pas aisé).
Eben Upton, fondateur de Raspberry Pi, a donné sur son blog une explication très pédagogique de ces dispositifs et de leur exploitation par les attaques Meltdown et Spectre.
Le kit d’exploitation et les articles de référence
Le site HacknDo fournit une boîte à outils pour, éventuellement, construire son programme d’attaque Spectre, mais surtout pour comprendre vraiment comment ça marche.
– Meltdown ;
– Spectre ;
– Eben Upton explique les attaques ;
– Pavel Boldin a publié un exemple d’exploitation de Meltdown ;
– Clémentine Maurice, qui travaille à l’université de Graz en Autriche dans une des équipes qui ont publié les failles, a prononcé lors de la conférence SSTIC 2017 un exposé très précis sur cette famille de vulnérabilités microélectroniques ;
– David Monniaux a publié des résumés pédagogiques (en français non informatique) pour Spectre et Meltdown ;
– bon article Hackndo ;
– par OVH, des explications techniques ;
– et vous pouvez écouter le passionnant podcast de NoLimitSecu sur le sujet.