Informatique confidentielle (Confidential computing) vs. informatique de confiance
La locution informatique confidentielle (Confidential computing) désigne un ensemble de technologies destinées à améliorer les garanties de sécurité et de protection du secret des données pour des traitements informatiques en nuage (Cloud Computing). Elle ne doit pas être confondue avec l’informatique de confiance (Trusted Computing), qui fait plutôt référence aux moyens de préserver les libertés individuelles et la vie privée de l’utilisateur de systèmes d’information, et qui fait l’objet par exemple du Règlement général sur la protection des données (RGPD) du Parlement européen et du Conseil du 27 avril 2016.
L’informatique confidentielle traite des aspects plus techniques de la protection des données et des traitements, aussi bien par l’introduction de nouveaux dispositifs matériels dans l’architecture microélectronique des systèmes que par l’adaptation des systèmes d’exploitation et des hyperviseurs de machines virtuelles du côté du logiciel.
Association for Computing Machinery
L’Association for Computing Machinery (ACM) partage avec l’IEEE (Institute of Electrical and Electronics Engineers) l’honneur de représenter sur la scène internationale les sciences et les technologies informatique, microélectronique et des réseaux. Je conseille l’adhésion, qui n’est pas très chère (99 dollars par an) et comporte un abonnement aux Communications of the ACM (CACM), une revue mensuelle de 130 et quelques pages, sur le modèle éditorial de Nature ou de Science, c’est-à-dire un ou deux articles de recherche, introduits chacun par une page qui permet aux non-spécialistes de comprendre de quoi il s’agit, trois ou quatre articles assez développés de synthèses scientifiques ou techniques, et pour le reste des actualités du domaine, des points de vue, des éditoriaux, des chroniques consacrées au droit et à l’enseignement de l’informatique. Depuis le 23 février 2024, les CACM sont en accès libre sur le site.
Outre des publications destinées aux membres et aux abonnés, l’ACM anime un site très riche d’articles en accès libre, ACM Queue, qui a publié en septembre 2023 un dossier de quatre articles qui présente de façon assez complète les aspects matériels et logiciels de l’informatique confidentielle. En voici un compte-rendu.
Rappel sur les machines virtuelles
Comme l’informatique en nuages (Cloud Computing), confidentielle de surcroît, repose entièrement sur la technologie des machines virtuelles, il peut être utile de rappeler brièvement ce dont il s’agit, quitte à renvoyer le lecteur vers un article plus complet en cas de besoin :
– une machine virtuelle est un programme informatique qui simule le fonctionnement d’un ordinateur, et qui peut donc exécuter les programmes qu’on lui soumet ;
– s’il faut simplement des systèmes isolés les uns des autres sur la même machine physique, il existe des systèmes de cloisonnement, nommés conteneurs (containers) qui procurent à chaque logiciel un environnement qui donne l’illusion de disposer d’une machine privée :
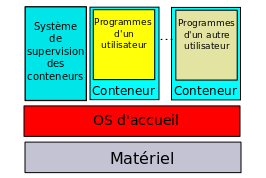
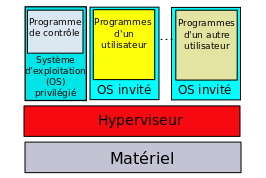
– s’il faut vraiment des machines virtuelles distinctes, mais toutes sur le même modèle de processeur (même architecture matérielle), il faudra interposer entre le matériel et les différentes copies du système d’exploitation un logiciel de simulation, nommé hyperviseur, mais les opérations élémentaires seront néanmoins effectuées par le matériel sous-jacent, ce qui évitera la grande diminution des performances qui serait entraînée par la simulation en logiciel des dites opérations :
Confidential Computing : Elevating Cloud Security and Privacy
par Mark Russinovich
Mark Russinovich est directeur technique (CTO) d’Azure, la plate-forme Cloud de Microsoft, ce qui ne l’empêche pas d’accueillir des myriades de machines virtuelles Linux de diverses obédiences.
Ce bref article d’introduction du dossier brosse le tableau des évolutions du paysage des systèmes d’information (SI) et de leur sécurité depuis une vingtaine d’années. C’est pendant la décennie des années 2000 que l’infonuagique (Cloud Computing) prit son essor pour submerger aujourd’hui le monde des infrastructures de services avec trois acteurs majeurs, AWS d’Amazon, Azure de Microsoft et Google Cloud, sans préjudice d’acteurs indépendants, comme en France OVH ou Scaleway.
Le développement de l’informatique en nuage a globalement amélioré la sécurité des systèmes d’informations qui ont migré vers ce type d’hébergement, parce que les opérateurs du Cloud disposent de plus de compétences et de moyens dans ce domaine que la plupart des entreprises, surtout celles qui sont trop petites pour affecter un poste d’ingénieur à ce sujet.
Mais les problèmes à résoudre ne sont plus tout à fait les mêmes : traditionnellement la sécurité du SI consistait à ce que les données et les traitements soient protégés à l’état statique (protection des infrastructures de stockage) et pendant leur circulation (sécurité du réseau et chiffrement des échanges de données). Avec le Cloud, les applications du SI sont exécutées sur des infrastructures dont l’entreprise n’a pas le contrôle, par des machines virtuelles pilotées par un hyperviseur [1] administré par l’opérateur infonuagique. Les données et les programmes doivent donc être protégés (c’est-à-dire chiffrés) y compris pendant les traitements, ce qui impose des modifications tant du matériel que des logiciels.
L’informatique confidentielle n’est pas juste une affaire de sécurité informatique : elle ouvre de nouvelles possibilités, comme par exemple la création de plates-formes collaboratives où différents acteurs pourraient interagir sans livrer leurs données. Les articles suivants du dossier développent plusieurs de ces perspectives.
Hardware VM Isolation in the Cloud
par David Kaplan
David Kaplan est chez AMD l’architecte en chef de la technologie Secure Encrypted Virtualization (SEV), leur plate-forme matérielle d’informatique confidentielle, dont son article expose les principes de mise en œuvre.
Dès avant l’apparition du Cloud il était clair que la façon la plus raisonnable de déployer un parc de logiciels quelque peu important était de multiplier des machines virtuelles spécialisées : il fallait juste des ordinateurs suffisamment puissants. Pour déployer des machines virtuelles sur un ordinateur physique celui-ci est piloté par un système d’exploitation réduit, dit hyperviseur, qui présente à chaque machine virtuelle une vision schématique de la machine physique sous-jacente :
Cette architecture à plusieurs niveaux demande de la puissance de calcul. Les machines virtuelles ont été inventées à la fin des années 1960 par les équipes IBM de Grenoble et de Cambridge, mais ce n’est que dans les années 2000 que les performances des ordinateurs ont permis de les utiliser en production. Ce fut dès lors le moyen le plus commode d’exploiter ses machines, et l’irruption du Cloud en a démultiplié les possibilités, en permettant la prolifération des machines virtuelles à la demande, en fonction des besoins, et partout sur le réseau.
Dès lors que la virtualisation devenait le modèle de calcul dominant (hormis pour les ordinateurs personnels), les entreprises de conception et de production de processeurs (Intel, AMD, ARM...) ont équipé leurs modèles destinés aux serveurs d’entreprise de dispositifs voués à la rendre plus efficace et plus sûre. C’est ainsi qu’AMD a équipé sa gamme de processeurs EPYC de la technologie Secure Encrypted Virtualization (SEV), qui comporte des instructions privilégiées spécialisées dans la gestion et l’isolation de machines virtuelles (ou de conteneurs).
Dès lors que le matériel et le système d’exploitation sous-jacent (l’hyperviseur) sont sous le contrôle d’un agent étranger (l’opérateur du Cloud), on ne peut plus se fier à rien. Au démarrage de chaque VM (Virtual Machine), une clé de chiffrement aléatoire lui est attribuée, et son usage est contrôlé par le hardware, afin que seule cette VM puisse lire le contenu de sa mémoire. Ainsi, les échanges entre le processeur et la mémoire sont chiffrés, ce qui suppose bien sûr des composants ultra-rapides et eux-mêmes isolés du reste du système. Si la VM doit communiquer avec l’hyperviseur, cela se fait au moyen de pages de mémoire partagées, chiffrées avec la clé de l’hyperviseur. Afin de se prémunir de l’opération malfaisante d’un hyperviseur malveillant, chaque traduction d’adresse virtuelle en adresse réelle est vérifiée a posteriori, afin de détecter une tentative d’introduction d’une page mémoire falsifiée dans l’espace d’une VM.
La gestion des interruptions est bien sûr cruciale. Ainsi, que se passe-t-il si l’hyperviseur transmet (« injecte ») une interruption à une VM pendant que celle-ci aurait justement masqué les interruptions ? Pour éviter les conséquences potentiellement fâcheuses d’un tel “unexpected behavior”, la VM peut choisir le mode de sécurité “Restricted Injection”.
Et ainsi de suite, l’article décrit toute une série de dispositifs diaboliques conçus pour que vous puissiez transférer dans le Cloud en toute confiance vos applications de publication de vidéos de chats les plus secrètes. Tous les processeurs récents pour serveurs sont équipés de dispositifs similaires.
Creating the First Confidential GPUs
par Gobikrishna Dhanuskodi, Sudeshna Guha, Vidhya Krishnan, Aruna Manjunatha, Michael O’Connor, Rob Nertney et Phil Rogers
Les auteurs de ce troisième article travaillent pour NVIDIA, le leader mondial des processeurs graphiques (Graphics Processing Unit, GPU). NVIDIA a renouvelé la conception des GPU au début des années 2000, et il s’est rapidement avéré que ces engins pouvaient servir à bien d’autres choses qu’à afficher des images, par exemple à faire fonctionner les réseaux convolutifs de l’intelligence artificielle. En effet, afficher une image consiste à appliquer un même traitement à un grand nombre de données identiques (tous les points d’une image de même couleur au même instant) : pour ce faire le GPU comporte un grand nombre de processeurs, dont chacun n’a besoin ni d’être très rapide (par rapport à un processeur généraliste, typiquement le CPU, ou Central Processing Unit), ni d’avoir une très grande précision en virgule flottante, simplement ils sont nombreux. Ces caractéristiques conviennent parfaitement à beaucoup d’algorithmes d’IA, et à d’autres calculs de simulation, bref, les GPU ont le vent en poupe.
Comme exposé pour l’article précédent, un GPU va échanger des données avec le processeur central qui exécute le programme principal et avec la mémoire, sans oublier les autres organes de l’ordinateur, et ces échanges doivent être protégés. Pour ce faire NVIDIA a adapté son matériel, et aussi son logiciel, puisqu’un GPU moderne contient beaucoup de logiciel, dit firmware ou micrologiciel.
Outre les problèmes analogues à ceux exposés par l’article précédent, le fonctionnement des GPU doit en résoudre un qui lui est propre : la protection des œuvres couvertes par le droit de la propriété intellectuelle, puisque par définition le GPU peut servir à regarder des vidéos en VoD ou achetées, dont il convient d’éviter le piratage (quoi que l’on en pense, c’est la loi, et quiconque faciliterait sa violation s’exposerait à ses rigueurs).
La solution élaborée par NVIDIA en collaboration avec Microsoft consiste à bâtir un TEE (Trusted Execution Environment, ou enclave) qui englobe une machine virtuelle confidentielle (CVM) exécutée sur le CPU (processeur central) et le système (matériel et logiciel) du GPU. Seule la CVM active a accès au GPU, l’hyperviseur ne peut effectuer qu’une seule opération : RESET.
Autrement on trouve les mêmes précautions que pour les processeurs AMD : clés de chiffrement à tous les étages, chiffrement de tous les échanges, vérification de leurs origines et de leurs destinations, exécution du code dans une enclave... Ce système de confidentialité des traitements fonctionne en coopération avec ceux des processeurs AMD et Intel.
Why Should I Trust Your Code ?
par Antoine Delignat-Lavaud, Cédric Fournet, Kapil Vaswani, Sylvan Clebsch, Maik Riechert, Manuel Costa et Mark Russinovich
Bien, les articles résumés ci-dessus nous ont convaincus, par des arguments cryptographiques relatifs au matériel et au logiciel, que le logiciel que nous exécutions dans le Cloud :
– était bien celui que nous avions décidé d’exécuter, sa signature cryptographique nous l’assure ;
– qu’il s’exécutait sans interférence malfaisante avec un tiers ;
– que d’éventuels tiers malveillants ne pouvaient observer ni les données ni les traitements que nous leur appliquions, parce que les traitements étaient effectués dans une enclave (ou Trusted Execution Environment, TEE) convenablement scellée par des dispositifs matériels (instructions machine dédiées).
Mais il reste une faille dans cette conviction : pouvons-nous faire confiance au code de ce logiciel ? N’a-t-il pas pu être altéré, éventuellement par un acteur légitime soudain sorti du droit chemin pour une raison ou pour une autre ?
Considérons par exemple un service d’IA auquel les internautes puissent soumettre leurs problèmes financiers, de santé, sentimentaux : il est hautement souhaitable que ces conversations ne puissent pas sortir de l’enclave où elles se déroulent, comme dans un confessionnal. Et pour cela il faut accorder sa confiance au logiciel.
On pourrait imaginer qu’un utilisateur particulièrement méfiant puisse télécharger le code source du logiciel, l’inspecter, le recompiler, vérifier que son résumé cryptographique (hash en parler informatique) est identique à celui qui était fourni, et roulez carrosse : c’est impossible, au premier chef parce que ces opérations demandent des compétences et du temps, alors que la fréquence des mises à jour des services infonuagiques est élevée, parfois hebdomadaire. Or les exemples abondent de vulnérabilités critiques découvertes parfois après plusieurs mois, voire plusieurs années d’impunité. Et lorsqu’un correctif arrive, les acteurs malveillants savent que la vulnérabilité est découverte, il faut donc corriger rapidement, on n’a pas le temps d’attendre que chacun ait inspecté le code, à supposer que ce soit possible. Bref, il faut trouver autre chose, une approche moins rigide.
Nos auteurs proposent à cet effet une architecture qui enregistre l’origine du code et qui établisse l’identité de ceux qui l’ont fourni et qui en sont comptables. Le cœur de cette architecture est un Code Transparency Service (CTS) qui maintient un registre public de tous les codes déployés pour des services d’informatique confidentielle, registre auquel on ne peut qu’ajouter des enregistrements, ni en retirer ni en modifier. Le registre est organisé selon un arbre de Merkle, ce qui garantit son inviolabilité.
Avant d’enregistrer un nouveau code le CTS lui applique des procédures de vérification d’intégrité, par exemple de contrôle des dépendances et des options de compilation, afin de se prémunir d’attaques par la chaîne d’approvisionnement. D’autres contrôles plus subtils sont précisés dans l’article.
La figure ci-dessous illustre la séquence d’opérations pour l’enregistrement d’une nouvelle version d’un code. Un acteur qui effectue une action sur le CTS doit émettre une déclaration (claim) qui décrit cette action, l’identifie et l’authentifie :

- le fournisseur de service examine la mise à jour et approuve son résumé cryptographique ;
- il soumet sa déclaration au CTS, qui applique sa procédure de contrôle, puis ajoute cette déclaration au registre, et enfin émet un certificat d’enregistrement ;
- le fournisseur de service charge l’image binaire de la mise à jour, accompagnée de sa déclaration et du certificat d’enregistrement, dans l’infrastructure du Cloud Service Provider (CSP) ;
- le CSP crée une enclave (TEE) qui charge et certifie la nouvelle image binaire par sa clé TLS (Transport Layer Security) ;
- le client se connecte à cette enclave en utilisant TLS ;
- le client reçoit (et peut vérifier) un certificat de la plate-forme, qui lui assure que le code qu’il invoque est bien celui qu’il pense, et que les vérifications adéquates ont bien été effectuées.
L’article donne bien des détails supplémentaires.
Analyse des menaces
Les auteurs ne manquent pas de préciser que, comme dans un roman d’Agatha Christie, toutes les parties concernées sont suspectes d’activités malfaisantes, de la plate-forme matérielle défectueuse à une enclave corrompue (après tout c’est du logiciel...) en passant par l’usurpation de l’identité d’un acteur légitime et par l’attaque sur le CTS...
La meilleure défense contre ces attaques est la transparence des services et de leur mise en œuvre, notamment celle du code. Et plus le service sera utilisé, plus il gagnera en robustesse, comme nous l’a appris l’expérience de SSL (Secure Sockets Layer) et de son successeur TLS.