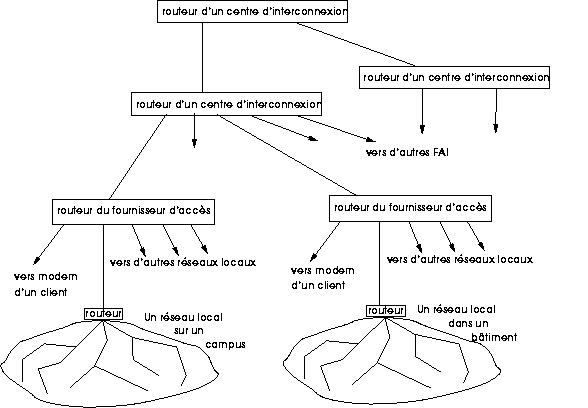
La figure 8.1 donne une représentation schématique de la topographie de l'Internet. Cette représentation est simplifiée, notamment elle est purement arborescente, alors que rien n'empêche une entreprise d'avoir plusieurs fournisseurs d'accès à l'Internet (FAI), ni un FAI d'être connecté à plusieurs centres d'interconnexion de niveau supérieur, ce qui complique le schéma et le transforme d'un arbre en un graphe connexe quelconque. Chaque noeud (ordinateur connecté, ou autre type d'équipement) est identifié par une adresse (dite adresse IP) unique à l'échelle mondiale, un peu comme un numéro de téléphone précédé de tous ses préfixes nationaux et régionaux. L'essentiel dans l'établissement d'une communication, c'est, à chaque noeud, de savoir quel est le prochain noeud sur l'itinéraire, et par quelle liaison l'atteindre. Les noeuds terminaux, origines ou destinations des communications, sont au sein des réseaux locaux de campus ou d'entreprise. Un routeur est un noeud particulier, doté de plusieurs interfaces réseau (et donc de plusieurs adresses), ce qui lui permet d'être connecté simultanément à plusieurs réseaux et de faire passer les paquets de données d'un réseau à un autre, en fonction de règles de routage qui auront été enregistrées dans sa mémoire.