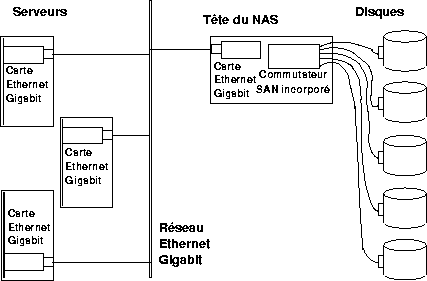
Chaque piste est découpée en secteurs. Une donnée est repérée par son numéro de piste depuis la plus extérieure (appelé numéro de cylindre, parce que l'ensemble des pistes de même rang, situées à la verticale l'une de l'autre, constitue un cylindre), son numéro de plateau (ou de tête de lecture, ce qui revient au même), le numéro du secteur qui la contient et le rang de l'octet dans le secteur. Chaque opération d'accès physique au disque transfère un ou plusieurs secteurs d'un coup, c'est le logiciel (du contrôleur ou du système d'exploitation) qui découpe ou assemble les données à l'intérieur des secteurs.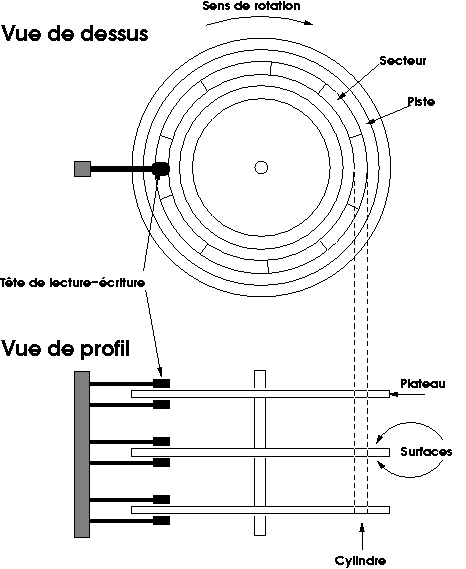
Le super-bloc pointe sur une autre structure de données cruciale, la i-liste (i pour index), qui est en quelque sorte une carte du système de fichiers, permettant d'y retrouver les fichiers. Pour les utilisateurs de tel ou tel autre système d'exploitation, la i-liste correspond à la FAT-table de Windows 98 ou à la MFT de NTFS, le système de fichiers de Windows 2000, ou encore à la VTOC (Volume table of contents) des grands systèmes IBM. Les éléments de la i-liste sont appelés i-noeuds. La i-liste doit refléter à chaque instant la structure logique et le contenu du système de fichiers, et comme celui-ci change à tout moment, au fur et à mesure que des fichiers sont créés, détruits, agrandis ou rétrécis, la i-liste doit posséder une structure très flexible.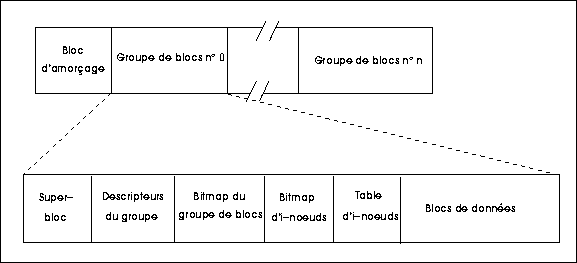
Si le fichier tient dans moins de douze blocs (et c'est le cas de la majorité des fichiers), il sera décrit par les pointeurs directs du i-noeud, et les pointeurs indirects ne seront pas utilisés, mais on voit que cette structure géométrique permet de décrire un très grand fichier (voir figure 5.3).
Photo_Tante_Léonie ou
fichier_clients_2002. Pour répondre à cette attente,
la plupart des systèmes d'exploitation proposent des répertoires
(en anglais directories), appelés parfois aussi dossiers
(folders) ou catalogues. Du point de vue de l'utilisateur, un système de fichiers se présente donc avec une structure d'arbre.
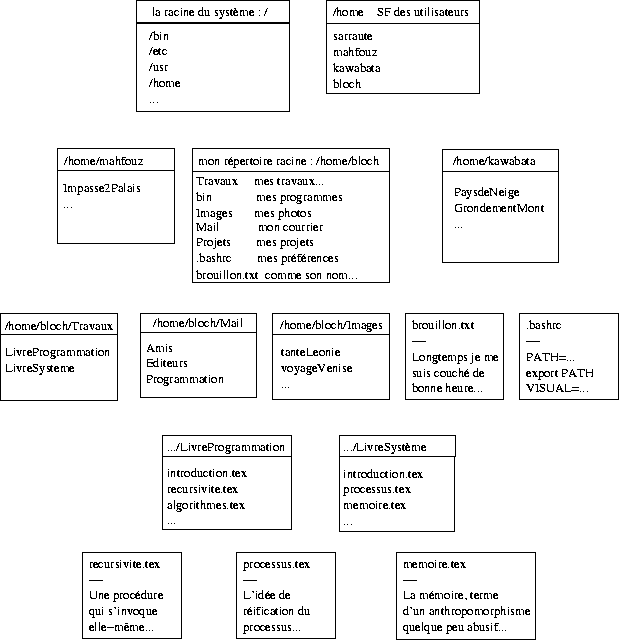
Les figures 5.5 et 5.6 représentent une partie d'un système de fichiers Unix. Un système Unix comporte au moins un système de fichiers, décrit par un répertoire appelé racine (root). Il comporte traditionnellement les sous-répertoires suivants :
Les serveurs comportent des HBA (Host Bus Adapters), qui ne sont pas autre chose que des contrôleurs SCSI adaptés au support Fibre Channel.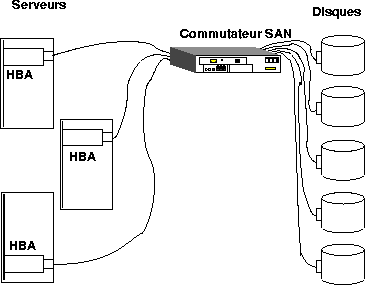
La figure 5.9 représente l'architecture d'un NAS. L'objet appelé « tête du NAS » est en fait un ordinateur équipé d'un système d'exploitation spécialisé qui ne fait que du service de fichiers. En général c'est un système Unix dépouillé de toutes les fonctions inutiles pour le système de fichiers, et spécialement optimisé pour ne faire que cela. Le plus souvent, la façon dont le NAS effectue la gestion de bas niveau de ses disques est... un SAN en Fibre Channel.