


Processus P1 Processus P2 ... ... Allocation de la ressource A ... ... Allocation de la ressource B ... ... Tentative d'allocation de la ... ressource B : échec, blocage ... ... ... ... Tentative d'allocation de la ... ressource A : échec, blocage ... ... Libération de la ressource A : ... hélas P1 n'arrivera jamais là. ... ... ... ... Libération de la ressource B : ... P2 n'y arrivera pas.
Table 3.1 : Étreinte fatale (l'axe du temps est vertical de haut en bas)
Le haut de ce diagramme correspond aux étapes initiales d'une opération d'entrée-sortie, elles sont compréhensibles avec les notions que nous possédons déjà :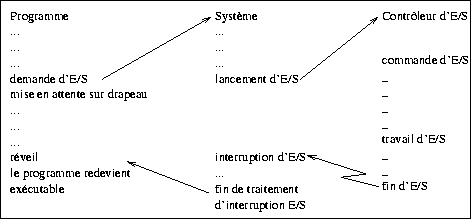
atomic_dec_and_test(v) et atomic_inc_and_test(v).