Les unités de contrôle1, arithmétique et d'entrée-sortie constituent à elles trois l'unité centrale, ou le processeur de l'ordinateur. Le processeur est constitué de circuits électroniques qui peuvent exécuter des actions. L'ensemble des actions « câblées » dans le processeur constitue le jeu d'instructions du processeur et détermine le langage élémentaire de son utilisation, appelé « langage machine ».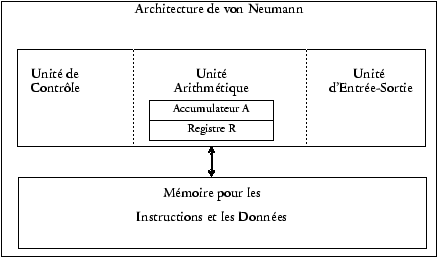
| H(S) = - |
|
pi × logapi |
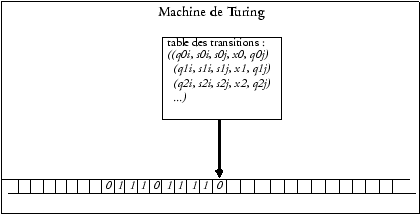
Le ruban mentionne successivement les nombres 4 et 3. Pour les additionner il suffit que la tête de lecture lise successivement les quatre chiffres unaires qui constituent le nombre 4, dont la fin sera indiquée par l'occurrence du signe zéro. Il faudra alors supprimer le zéro et réécrire d'une case à droite les chiffres du nombre 3, jusqu'à la rencontre d'un signe zéro, qui subira le même traitement, pour obtenir 7. L'écriture de la table des transitions constituera pour le lecteur un exercice amusant.